Long-tail knowledge and collective intelligence
Wikipedia makes a distinction [1] between common knowledge and general knowledge. Common knowledge “is knowledge that is known by everyone or nearly everyone, usually with reference to the community in which the term is used.” [2] Cyc project collected 24.5 million pieces of such information [3]. General knowledge is available for example in encyclopedias. Wikipedia contains about 40 million articles [4] resulting probably in billions pieces of information.
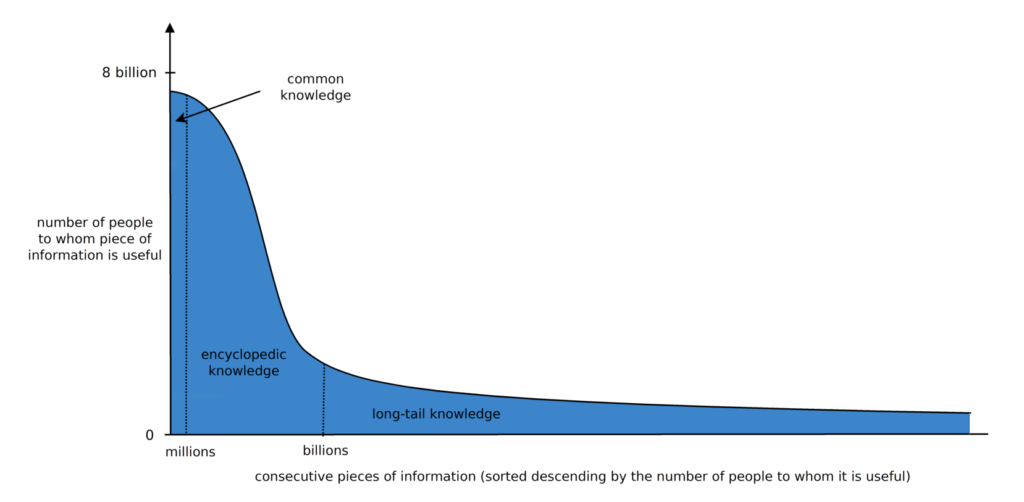
There is also large amount of important knowledge that is too specific to be put in an encyclopedia, for example knowledge about my car or food I eat (see the picture below and the description of the long tail on Wikipedia). The method described in the post Yet another idea of collaboratively edited knowledge base aims to collect such information and integrate it with other types of information. Due to the large amount of information, it seems reasonable to collect it by crowdsourcing [5][6][7]. Crowdsourcing of knowledge can additionally simplify access to collected knowledge and facilitate its exchange between people, potentially increasing our collective intelligence. The collected knowledge could be used by both people and computers.
Related systems and concepts
- Cyc – common knowledge base created by experts
- Open Mind Common Sense – common knowledge base created by crowdsourcing
- Mindpixel – common knowledge base created by crowdsourcing
- Wikidata – data used in Wikipedia infoboxes, collected using a method similar to that proposed in the post Yet another idea of collaboratively edited knowledge base
- Semantic Web
[1] Wikipedia: Outline of knowledge – By scope
[2] Wikipedia: Common knowledge
[3] Wikipedia: Cyc
[4] Wikipedia: Size comparisons
[5] C. Sarasua, E. Simperl, N. Noy, A. Bernstein, J. M. Leimeister: Crowdsourcing and the SemanticWeb: A Research Manifesto, Human Computation, Vol 2, No 1, 2015
[6] M. Sabou, L. Aroyo, K. Bontcheva, A. Bozzon, R. K. Qarout: Semantic Web and Human Computation: the Status of an Emerging Field, Semantic Web, Vol 9, No 3, 2018
[7] Push Singh: The Open Mind Common Sense Project, 2002, originally published on KurzweilAI.net
